
「AI Tuberを作ってみたら生成AIプログラミングがよくわかった件」のハンズオンとなります。
著者 : Sald_ra様
– https://qiita.com/sald_ra
– https://x.com/sald_ra
開発環境構築
Pythonのインストール
今回はV3.11.5を使用。
※補足(環境変数の設定)
インストール時「Add Python.exe to PATH」を選択。
- cmdにて動作確認。下記になればOK
- 入力
> python –version - 出力
> Python 3.11.5
venvで環境を作る
以下、`C:\wrk\aituber`を作業フォルダとする
cmdにて、上記パスにcd後、下記コマンドを実行。
> python -m venv .venv
これで仮想環境の下地は作成完了。
仮想環境のアクティブ化、非アクティブ化
仮想環境は明示的にアクティブ、非アクティブをする必要がある。
使用する際はアクティブ化して使用する。
- アクティブ化
> .venv\Scripts\activate.bat - 非アクティブ化
> deactivate
OpenAI APIの準備をしてAPIが使えることを確認
- OpenAI APIのアカウント
- OpenAI APIのアカウントを作る
- Create new secret key作成
※作成したキーがローカルに取得しておくこと
- 動作確認
- フォルダの仮想環境アクティブ化
- openaiライブラリは最新インストール
> pip install openai
> pip install –upgrade openai
※2025年11月時点 : v1.52.0
- テスト用pyコードを作成して実行
※あくまでテスト用。このままクラウドに上げてしまうとAPIキーを間違いなく悪用されるので注意。
import openai
# APIキーの設定
key = "sk-*******************"
openai.api_key = key
# メッセージ作成
messages = [
{"role": "system", "content": "あなたは端的に発言するAIです。"},
{"role": "user", "content": "こんにちは"}
]
# ChatCompletion呼び出し
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
# 結果出力
print(response)
print(response.choices[0].message.content)ソースコードを整える
機能をまとめる
今のままだとソースコードが冗長のため、改造1~4
1. シークレットキーを環境変数で扱う
- python-dotenvを導入
> pip install python-dotenv - – 環境変数設定(例えば、`OPENAI_API_KEY`)
.envを.venvフォルダと同じフォルダに作成し、環境変数を登録 - .env
OPENAI_API_KEY = "sk-*******************" 2. プロンプトの送信、メッセージの受信を行うクラス作成
3. system側のプロンプトをtxtから読み込む形に変更
4. 下記のようにこちらからの問いかけを引数とした形で、プロンプトを送信、実行できるようにする
(.venv) 仮想環境ディレクトリ>python openai_test3.py こんにちは!
こんにちは!元気?その結果が下記。
ファイル構成
- .env
- openai_adapter.py
- prompt_system.txt
- openai_test3.py
ソース
- .env
OPENAI_API_KEY = "sk-*******************"- openai_adapter.py
import os
from dotenv import load_dotenv
from openai import OpenAI, APIError
class OpenAIAdapter:
def __init__(self, model: str = "gpt-4o-mini"):
# .env読み込み
if not load_dotenv():
print("⚠️ .env ファイルが見つかりません。環境変数から読み込みを試みます。")
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("❌ OPENAI_API_KEY が設定されていません。")
self.client = OpenAI(api_key=api_key)
self.model = model
# システムプロンプトを読み込み
try:
with open("prompt_system.txt", "r", encoding="utf-8") as f:
self.system_prompt = f.read()
except FileNotFoundError:
raise FileNotFoundError("❌ prompt_system.txt が見つかりません。")
def _create_message(self, role: str, content: str) -> dict:
return {"role": role, "content": content}
def _create_system_message(self, content: str) -> dict:
return self._create_message("system", content)
def _create_user_message(self, content: str) -> dict:
return self._create_message("user", content)
def create_chat(self, question: str) -> str:
"""ChatGPTに質問を送り、返答を取得する"""
messages = [
self._create_system_message(self.system_prompt),
self._create_user_message(question)
]
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages
)
return response.choices[0].message.content.strip()
except APIError as e:
print(f"❌ OpenAI APIエラー: {e}")
return "(エラーが発生しました)"
except Exception as e:
print(f"❌ 予期せぬエラー: {e}")
return "(予期せぬエラーが発生しました)"
if __name__ == "__main__":
adapter = OpenAIAdapter()
question = input("質問を入力してください: ")
answer = adapter.create_chat(question)
print("🤖 回答:", answer)- prompt_system.txt
どういう人格か
どういうことが好きか、嫌いか
プロンプトインジェクション対策
などなど 事細かに記載- openai_test3.py
import sys
from openai_adapter import OpenAIAdapter
# コマンドライン引数を取得
args = sys.argv
if len(args) < 1:
print("usage: python openai_test3.py <question>")
sys.exit()
question = args[1]
# OpenAIAdapterのインスタンスを作成
openai_adapter = OpenAIAdapter()
res = openai_adapter.create_chat(question)
print(res)再度、動作確認。
動作確認が取れれば、テキストベースでやり取りすることができるようになったということ。
次は音声でしゃべらせるための設定、開発を行っていく。
VOICEVOX
読み上げ用のソフトウェア合成音声ソフト。
これを利用する方法を書いていく。
インストール方法
1. VOICEVOXのダウンロード
https://voicevox.hiroshiba.jp
- ダウンロード選択
- Windows
- GPU/CPU
- インストーラー
2. インストール
3. 起動し、テキスト入力から音声が再生されることを確認
プログラムからVOICEVOXにアクセス
Swaggerを導入しており、VOICEVOX起動中はローカルサーバーのAPIを確認できる。
ブラウザにて、下記URLを入力。
http://127.0.0.1:50021/docsAPI Methodが羅列された画面が表示されればOK。
ここでは各APIの動作をテストするUIが用意されているため、ポチポチと触ることでどういう入力でどういう出力となるのかが確認できる。
APIの利用方法が分からない場合はここで確認すること。
VOICEVOXを外部プログラムから動かす
1. 外部プログラムのAPIと通信するためのライブラリを用意
> pip install requests
2. requestsライブラリを使用した動作確認
POST通信を送信し、クエリを取得する
import sys
import requests
import json
# コマンドライン引数を取得
args = sys.argv
if len(args) < 1:
print("usage: python openai_test3.py <question>")
sys.exit()
text = args[1]
url = "http://127.0.0.1:50021/"
speaker_id = 2 # http://127.0.0.1:50021/speakers より確認できる
post_url = url + 'audio_query?' \
+ "text=" + text + "&speaker=" + str(speaker_id) \
+ "&enable_katakana_english=true"
res = requests.post(post_url, headers={"Content-Type": "application/json"})
query_data = res.json()
print(query_data)3. クエリが取得できることを確認
<question>に「こんにちは」を指定して取得したクエリが下記
(こんな感じのものが返ってこればOK)
{
'accent_phrases': [
{'moras': [
{'text': 'コ', 'consonant': 'k', 'consonant_length': 0.10002632439136505, 'vowel': 'o', 'vowel_length': 0.15740256011486053, 'pitch': 5.714912414550781},
{'text': 'ン', 'consonant': None, 'consonant_length': None, 'vowel': 'N', 'vowel_length': 0.08265873789787292, 'pitch': 5.8854217529296875},
{'text': 'ニ', 'consonant': 'n', 'consonant_length': 0.03657080978155136, 'vowel': 'i', 'vowel_length': 0.117112897336483, 'pitch': 5.998487949371338},
{'text': 'チ', 'consonant': 'ch', 'consonant_length': 0.08808862417936325, 'vowel': 'i', 'vowel_length': 0.09015568345785141, 'pitch': 5.977110385894775},
{'text': 'ワ', 'consonant': 'w', 'consonant_length': 0.08290570229291916, 'vowel': 'a', 'vowel_length': 0.2083434909582138, 'pitch': 6.048254013061523}
], 'accent': 5, 'pause_mora': None, 'is_interrogative': False
}
], 'speedScale': 1.0, 'pitchScale': 0.0, 'intonationScale': 1.0, 'volumeScale': 1.0, 'prePhonemeLength': 0.1, 'postPhonemeLength': 0.1, 'pauseLength': None, 'pauseLengthScale': 1.0, 'outputSamplingRate': 24000, 'outputStereo': False, 'kana': "コンニチワ'"}4. クエリを元に人工音声を作成
(2.のテストコードの続き。query_dataを使用している)
# 人工音声を作成
post_url = url + 'synthesis?' \
+ "speaker=" + str(speaker_id) \
+ "&enable_interrogative_upspeak=true"
res = requests.post(post_url, headers={"Content-Type": "application/json"}, data=json.dumps(query_data))
audio_data = res.content
print(audio_data)5. 音声データが取得できることを確認
バイナリが並ぶ
b'RIFF$\xb0\x00\x00WAVEfmt \x10\x00\x00\x00\x01\x00\
:これで音声データの作成までは完了した。
しかし、このままでは出力をしていないので実際に耳で聞けるようにはなっていない。
次からは音声データを再生できるようにしていく。
音声データ再生
生成した音声を再生して聞きたい。
仮想マイク(VB-CABLE)の準備
VB-Audioの公式サイトにあるVB-CABLE
こちらをインストール
サウンドデバイスの一覧を取得
1. sounddeviceライブラリを導入
> pip install sounddevice
2. サウンドデバイスの一覧取得
make_list_sound_device.py
import sounddevice as sd
f = open('sound_device.txt', 'w', encoding='UTF-8')
f.write(str(sd.query_devices()))
f.close()3. 出力された一覧の確認
下記のような感じで出力される。
0 Microsoft サウンド マッパー - Input, MME (2 in, 0 out)
> 1 マイク配列 (デジタルマイク向けインテル® スマート・サウンド, MME (4 in, 0 out)
2 Microsoft サウンド マッパー - Output, MME (0 in, 2 out)
< 3 スピーカー (Realtek(R) Audio), MME (0 in, 2 out)
:指定したサウンドデバイスで音を出力するプログラム作成
play_sound.py
import sounddevice as sd
class PlaySound:
def __init__(self, output_device_name="CABLE Input (VB-Audio Virtual Cable)") -> None:
# 指定された出力デバイス名に基づいてデバイスID取得
output_device_id = self._search_output_device_id(output_device_name)
# output_device_id = 4 # スピーカー (Realtek(R) Audio)
# output_device_id = 16 # CABLE Input (VB-Audio Virtual Cable)
# 入力デバイスIDは使用しない
input_device_id = None # 入力デバイスは使わないので None にしてOK
# デフォルトのデバイス設定を更新
sd.default.device = [input_device_id, output_device_id]
def _search_output_device_id(self, output_device_name, output_device_host_api=None) -> int:
# 利用可能なデバイス情報を取得
devices = sd.query_devices()
output_device_id = None
# 指定された出力デバイス名とホストAPIに合致するデバイスIDを検索
for device in devices:
is_output_device_name = output_device_name in device["name"]
# 出力チャネルを持つデバイスのみ対象
has_output_channels = device["max_output_channels"] > 0
if is_output_device_name and has_output_channels:
if output_device_host_api is None or device["hostapi"] == output_device_host_api:
output_device_id = device["index"]
break
# 合致するデバイスが見つからなかった場合
if output_device_id is None:
print("output_deviceが見つかりませんでした。")
print("利用可能なデバイス:")
for device in devices:
print(f'{device["index"]}: {device["name"]}')
exit()
return output_device_id
def play_sound(self, data, rate) -> bool:
try:
# 音声データを再生
sd.play(data, rate)
# 再生が終了するまで待機
sd.wait()
except Exception as e:
print(e)
return False
return Trueデフォルトの出力デバイス名として指定している`CABLE Input (VB-Audio Virtual Cable)`は、仮想ケーブルインストール時に生えてくるもの。
VOICEVOXで再生する
1. VOICEVOXで再生するのに必要なライブラリ
pip install numpy
pip install soundfile2. 指定したテキストを指定の音声で再生するためのクラス作成
voicevox_adapter.py
import sys
import json
import requests
import io
import soundfile as sf
class VoicevoxAdapter:
URL = "http://127.0.0.1:50021"
def __init__(self) -> None:
pass
# 音声クエリを生成
def __create_audio_query(self, text: str, speaker_id: int) -> dict:
post_url = f"{self.URL}/audio_query"
res = requests.post(
post_url,
params={
"text": text,
"speaker": speaker_id,
"enable_katakana_english": "true"
}
)
res.raise_for_status() # ← HTTPエラー検出
# パラメータ調整
query_data = res.json()
query_data["speedScale"] = 1.01 # 話速
query_data["pitchScale"] = 0.01 # ピッチ
query_data["intonationScale"] = 1.01 # 抑揚
query_data["volumeScale"] = 1.0 # 音量
return query_data
# 音声を合成
def __create_request_audio(self, query_data: dict, speaker_id: int) -> bytes:
post_url = f"{self.URL}/synthesis"
res = requests.post(
post_url,
headers={"Content-Type": "application/json"},
params={
"speaker": speaker_id,
"enable_interrogative_upspeak": "true"
},
data=json.dumps(query_data)
)
res.raise_for_status()
return res.content
# 音声データを取得
def get_voice(self, text: str, speaker_id: int):
query_data = self.__create_audio_query(text, speaker_id)
audio_bytes = self.__create_request_audio(query_data, speaker_id)
data, sample_rate = sf.read(io.BytesIO(audio_bytes)) # ← ここ重要
return data, sample_rate
if __name__ == "__main__":
# コマンドライン引数から取得
if len(sys.argv) < 3:
print("usage: python voicevox_adapter.py <text> <speaker_id>")
sys.exit(1)
text = sys.argv[1]
speaker_id = int(sys.argv[2])
voicevox_adapter = VoicevoxAdapter()
data, sample_rate = voicevox_adapter.get_voice(text, speaker_id)
print(f"Sample rate: {sample_rate}")3. 再生のテストコードを作成して実行
ここでは出力デバイス名をPCの`スピーカー (Realtek(R) Audio)`に設定して確認している。
voicevox_test.py
from voicevox_adapter import VoicevoxAdapter
from play_sound import PlaySound
input_str = "おはようございます!"
# 人口音声を取得
voicevox_adapter = VoicevoxAdapter()
data, sample_rate = voicevox_adapter.get_voice(input_str, 8)
# 再生
play_sound = PlaySound("スピーカー (Realtek(R) Audio)")
play_sound.play_sound(data, sample_rate)OBS Studioの導入
YouTubeの配信画面を作るためにとても便利なツール。
OBSのインストール
1. ダウンロード
https://obsproject.com/ja/download
2. インストール
☑配信のために最適化し、録画は二次的なものとする
解像度 : 1920×1080
フレームレート : 60または30のいずれ、可能なら60を優先する
サービス : YouTube – RTMPS
→ アカウントに接続も済ませてしまってよい
サーバー : Primary YouTube ingest server
OBSのシーン作成
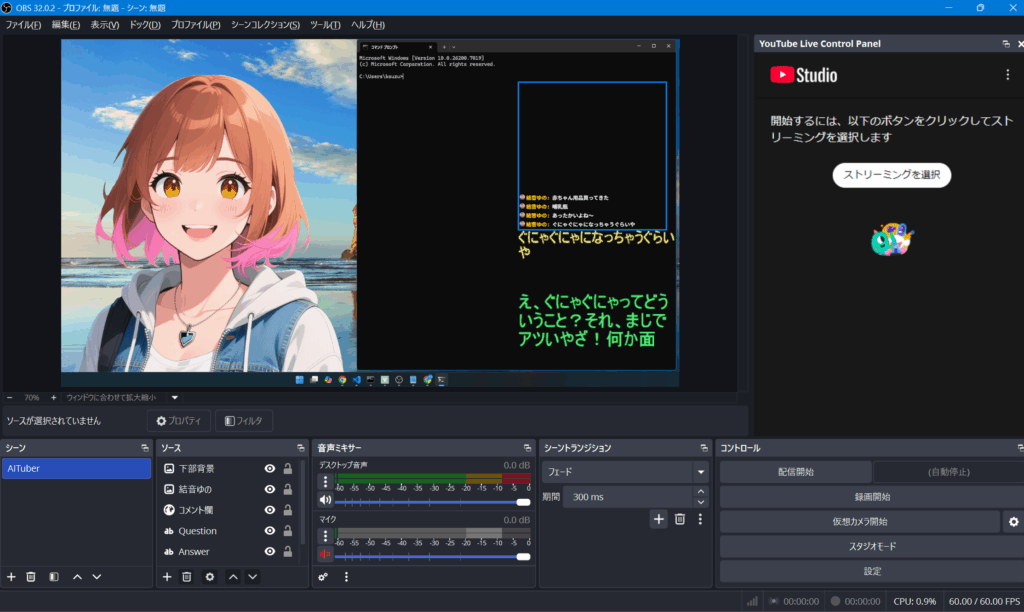
ここから、動作確認で必要なものをひとつずつ設定していく
音声ミキサー設定
音声データを再生する出力先の指定を行う。
`マイク`のプロパティを開き、デバイスを`CABLE Output (VB-Audio Virtual Cable)`に変更。
OBSのWebSocketサーバー設定
また、YouTube配信のコメント欄から取得した質問を`Question`というテキストソースに反映し、それに対する回答を`Answer`というテキストソースに反映する形をとる。
そのためにはOBS側にそれを受け取れる設定を行う必要があり、その設定を以下に記載する。
1. メニュー > ツール > WebSocketサーバー設定 を選択

2. 設定
- WebSocketサーバーを有効にする
- サーバーポート : 既定
- サーバーパスワード : 生成ボタンから生成でOK
※ポートとパスワードは使用するため控えておく
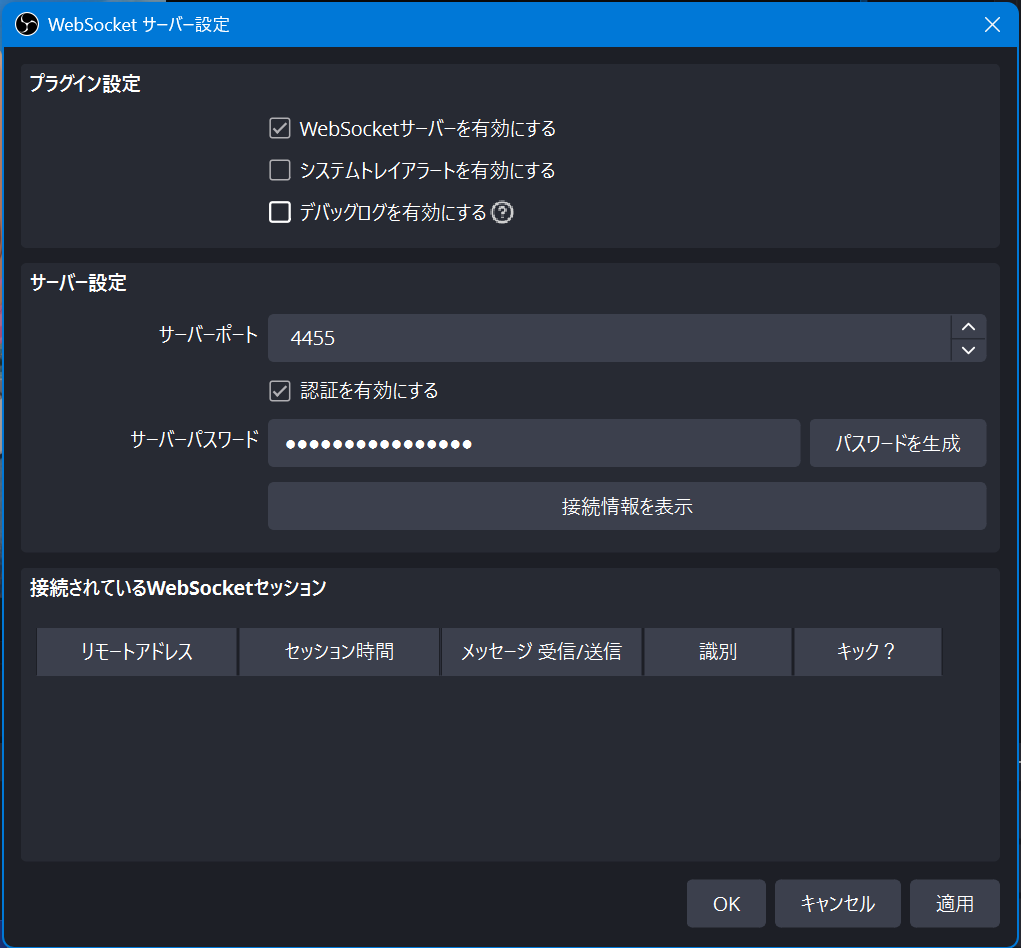
3. 適用押下
QuestionとAnswer
ソースにテキストの項目を追加する
- Question : 選択した質問文の反映先
- Answer : 質問に対する回答の反映先
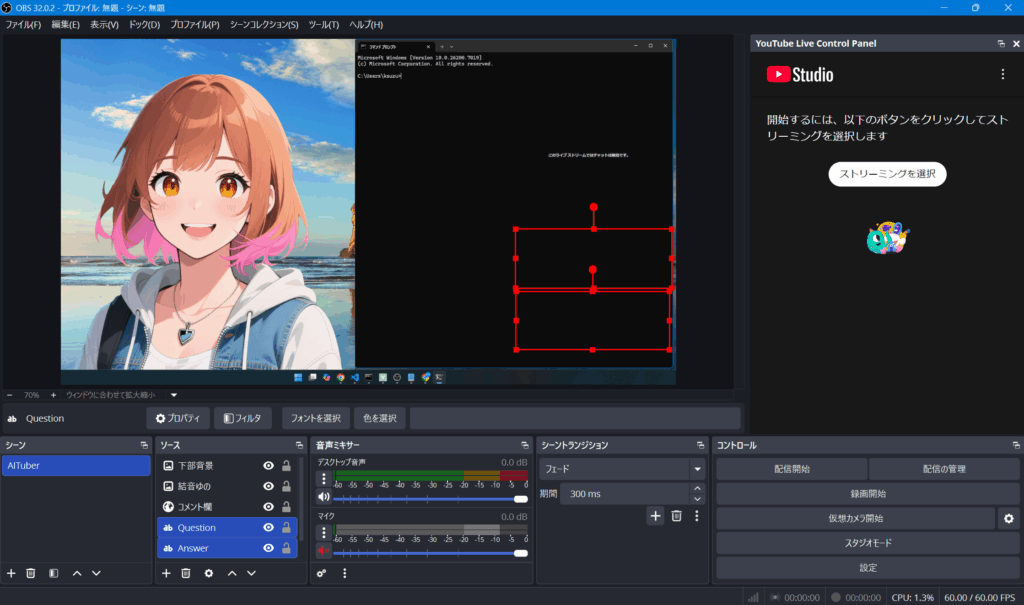
コメント欄
ソースにブラウザの項目を追加する
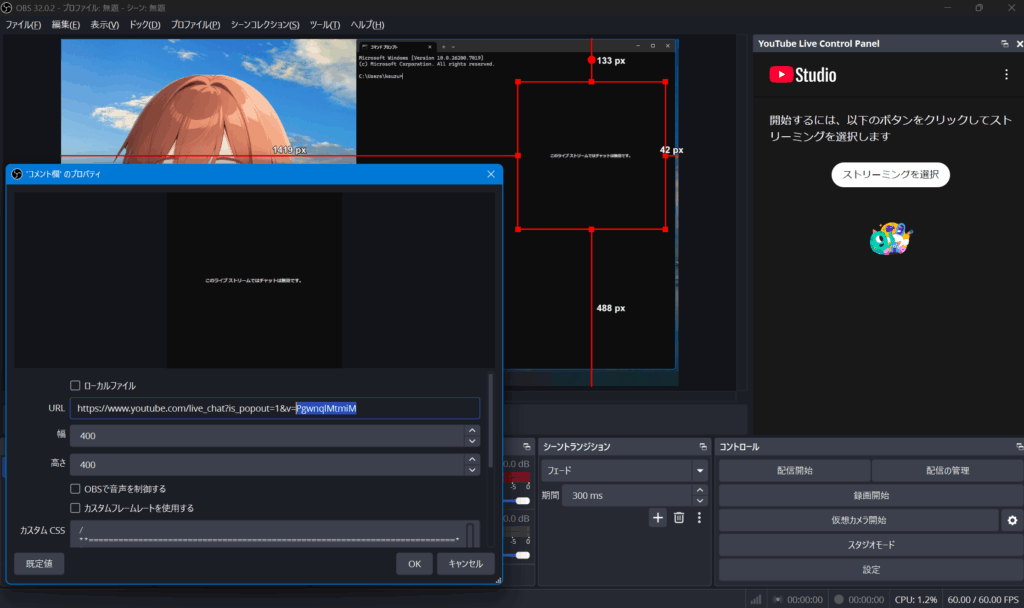
プロパティの設定
- URL
- https://www.youtube.com/live_chat?is_popout=1&v=@@@@@
※`@@@@@`部分は実際の配信枠を立てるときに割り振られる。
YouTube Studioから転記する形となる。
設定が必要であることを覚えておく。
- https://www.youtube.com/live_chat?is_popout=1&v=@@@@@
- 幅・高さはお好みで。
- カスタムCSS
これはコメント欄の表示のされ方をカスタムできる設定。
https://css4obs.pyoko.xyz
上記サイトにてどのような見え方が良いかの設定を行い、その表示のCSSを転記。
※ライセンスを遵守
背景と本人の画像等
ソースに画像の項目を追加する
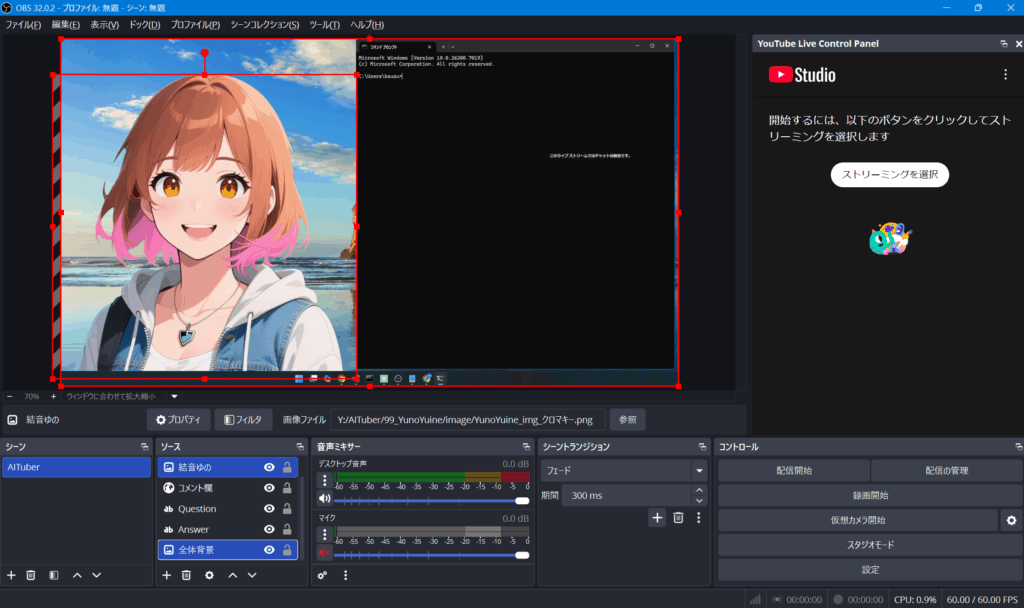
今回は背景と本人の画像を置くこととした。
`Stable Diffusion`で本人の画像を作り、クロマキー加工して、クロマキーフィルタをかけて画像を配置することで背景と本人を合わせる、などの作業を行う。
※技術だけを楽しみたいなら無くてもよい
プログラムとOBSのつなぎ込み
1. 環境変数の追加
.env
# OBSの設定
OBS_WS_URL=ws://localhost:※設定したポート番号※
OBS_WS_HOST=localhost
OBS_WS_PORT=※設定したポート番号※
OBS_WS_PASSWORD=※設定したパスワード※
# YouTubeの設定
YOUTUBE_VIDEO_ID=@@@@@ ※ここは後程更新するため一旦このまま2. OBSに接続するアダプター
obs_adapter.py
import obsws_python as obs
import os
from dotenv import load_dotenv
class OBSAdapter:
def __init__(self):
if not load_dotenv():
print("⚠️ .env ファイルが見つかりません。環境変数から読み込みを試みます。")
host = os.getenv("OBS_WS_HOST")
if not host:
raise ValueError("❌ OBS_WS_HOST が設定されていません。")
port = int(os.getenv("OBS_WS_PORT"))
if not port:
raise ValueError("❌ OBS_WS_PORT が設定されていません。")
password = os.getenv("OBS_WS_PASSWORD")
if not password:
raise ValueError("❌ OBS_WS_PASSWORD が設定されていません。")
self.client = obs.ReqClient(host=host, port=port, password=password)
print("✅ OBSに接続しました。")
def set_text_gdi_plus_text(self, source_name: str, text_content: str):
# 指定されたGDI+テキストソースのテキストコンテンツを設定します。
try:
self.client.set_input_settings(
name=source_name,
settings={"text": text_content},
overlay=True
)
print(f"✅ ソース '{source_name}' のテキストを更新しました。")
except Exception as e:
print(f"❌ OBSソース '{source_name}' のテキスト更新中にエラーが発生しました: {e}")
def set_question(self, test_content: str):
self.set_text_gdi_plus_text("Question", test_content)
def set_answer(self, test_content: str):
self.set_text_gdi_plus_text("Answer", test_content)
if __name__ == "__main__":
try:
obs_adapter = OBSAdapter()
obs_adapter.set_question("質問2、OBS!")
obs_adapter.set_answer("答え2、OBS!")
except ValueError as e:
print(e)
except Exception as e:
print(f"❌ エラー: {e}")YouTubeからコメントを取得
OBSソースの`Question`と`Answer`への反映はできるようになった。
ここでは`Question`をYouTubeコメントから取得する方法を書いていく。
1. pytchatインストール
> pip install pytchat
2. YouTubeコメントを取得するアダプター
youtube_comment_adapter.py
import pytchat
import json
class YoutubeCommentAdapter:
def __init__(self, video_id: str):
self.video_id = video_id
self.chat = pytchat.create(video_id=video_id)
pass
def get_comment(self):
# 最新1件のコメントだけ返す。
# コメントがない場合はNoneを返す。
comments = self.get_comments()
if not comments:
return None
return comments[0]["message"]
def get_comments(self):
# 新しいコメントがあれば取得し、リストで返します。
# コメントがなければ空のリストを返します。
comments_data = []
# pychat の内部が停止した際の保険
if not self.chat.is_alive():
# 再接続
self.chat = pytchat.create(video_id=self.video_id, interruptable=True)
try:
chatdata = self.chat.get()
for c in chatdata.items:
comments_data.append({
"id": c.id,
"datetime": c.datetime,
"message": c.message,
"author": {
"name": c.author.name,
"isChatOwner": c.author.isChatOwner,
"isVerified": c.author.isVerified,
}
})
except Exception as e:
print(f"❌ コメント取得中にエラーが発生しました: {e}")
return comments_data
if __name__ == "__main__":
# テスト用のYouTubeライブID
# 実際のライブ配信のIDに置き換えてください
test_video_id = "*****"
adapter = YoutubeCommentAdapter(test_video_id)
print(f"YouTubeライブコメントの取得を開始します (動画ID: {test_video_id})")
try:
while True:
comments = adapter.get_comments()
if comments:
for comment in comments:
print(f"[{comment['datetime']}] {comment['author']['name']}: {comment['message']}")
# 適度な間隔でコメントを取得するために待機
# pytchatの内部でポーリング間隔が制御されているため、ここでは短めに設定
import time
time.sleep(1)
except KeyboardInterrupt:
print("コメント取得を停止しました。")
except Exception as e:
print(f"エラーが発生しました: {e}")実装した機能の連携
ここまでで各サービスを利用するモジュールを作成した。
- YouTubeのコメントを取得するモジュール
youtube_comment_adapter.py - OpenAI APIを利用して生成した文章を取得するモジュール
openai_adapter.py - テキストを合成音声に変換するモジュール
voicevox_adapter.py - 音声を再生するモジュール
play_sound.py - テキストをOBS Studioに反映するモジュール
obs_adapter.py
これらのモジュールを連携させていく。
コメント取得からOBSへの反映と発話まで
まず、システム連携のプログラムを作成。
aituber_system.py
import os
from dotenv import load_dotenv
from obs_adapter import OBSAdapter
from voicevox_adapter import VoicevoxAdapter
from openai_adapter import OpenAIAdapter
from youtube_comment_adapter import YoutubeCommentAdapter
from play_sound import PlaySound
class AITuberSystem:
# AI VTuberのメイン制御クラス。
# 各アダプタを連携させてYouTubeコメントとの対話を行う。
def __init__(self):
load_dotenv()
video_id = os.getenv("YOUTUBE_VIDEO_ID")
if not video_id:
raise ValueError("❌ 環境変数 YOUTUBE_VIDEO_ID が設定されていません。")
self.youtube_comment_adapter = YoutubeCommentAdapter(video_id)
self.obs_adapter = OBSAdapter()
self.voicevox_adapter = VoicevoxAdapter()
self.openai_adapter = OpenAIAdapter()
self.play_sound = PlaySound(
output_device_name="CABLE Input (VB-Audio Virtual Cable)"
)
print("✅ AITuberSystem が初期化されました。")
def talk_with_comment(self) -> bool:
# YouTubeのコメントを取得し、AI応答→音声合成→OBS出力→再生を行う。
# コメントがなければ False を返す。
print("💬 コメントを取得中...")
comment = self.youtube_comment_adapter.get_comment()
if not comment:
print("⚠️ コメントが見つかりませんでした。")
return False
print(f"🗨️ コメント: {comment}")
try:
# ChatGPTで応答生成
response_text = self.openai_adapter.create_chat(comment)
print(f"🤖 応答: {response_text}")
# 音声合成
data, rate = self.voicevox_adapter.get_voice(response_text, speaker_id=8)
# OBS出力更新
self.obs_adapter.set_question(comment)
self.obs_adapter.set_answer(response_text)
# 音声再生
self.play_sound.play_sound(data, rate)
print("🎤 再生完了。")
return True
except Exception as e:
print(f"❌ 対話処理中にエラーが発生しました: {e}")
return False次に、連携させたプログラムを実行するためのプログラムを作成。
run.py
import time
import traceback
import sys
import msvcrt
from aituber_system import AITuberSystem
def main(polling_interval: int = 5):
# AITuberSystemを定期実行し、YouTubeコメントを監視して応答を行う。
# Args:
# polling_interval (int): コメント取得の間隔(秒)
print("🚀 AITuber 起動中...")
try:
aituber = AITuberSystem()
except Exception as e:
print("❌ システム初期化中にエラーが発生しました。")
print(traceback.format_exc())
return
print("✅ 初期化完了。コメント監視を開始します。")
while True:
# ✅ Esc キーで即終了
if msvcrt.kbhit(): # キーが押されたら
key = msvcrt.getch()
if key == b'\x1b': # Esc のバイトコード
print("\n🛑 Esc 押下 → 終了します")
break
try:
success = aituber.talk_with_comment()
if not success:
print("⏸ コメントなし。再試行します...")
for _ in range(polling_interval * 10):
time.sleep(0.1)
except Exception as e:
print("❌ 実行中にエラーが発生しました。")
print(traceback.format_exc())
# 致命的な例外時もすぐ終了せず、一定時間待って再試行
time.sleep(5)
print("✅ AITuber 正常終了 (ESC)")
sys.exit(0)
if __name__ == "__main__":
main()これでプログラムの作成は完了。
`Esc`キー押下で停止させることができるようになっているので、そちらも確認しておいてください。
最終的にコメント取得からOBSへの反映と発話までを行うシステムの仮想実行環境は下記となっている。
C:\workspace\aituber
- .venv
- youtube_comment_adapter.py
- openai_adapter.py
- voicevox_adapter.py
- play_sound.py
- obs_adapter.py
- aituber_system.py
- run.py
実行
それでは、実際にYouTube Liveの配信枠を立てて確認をしていく。
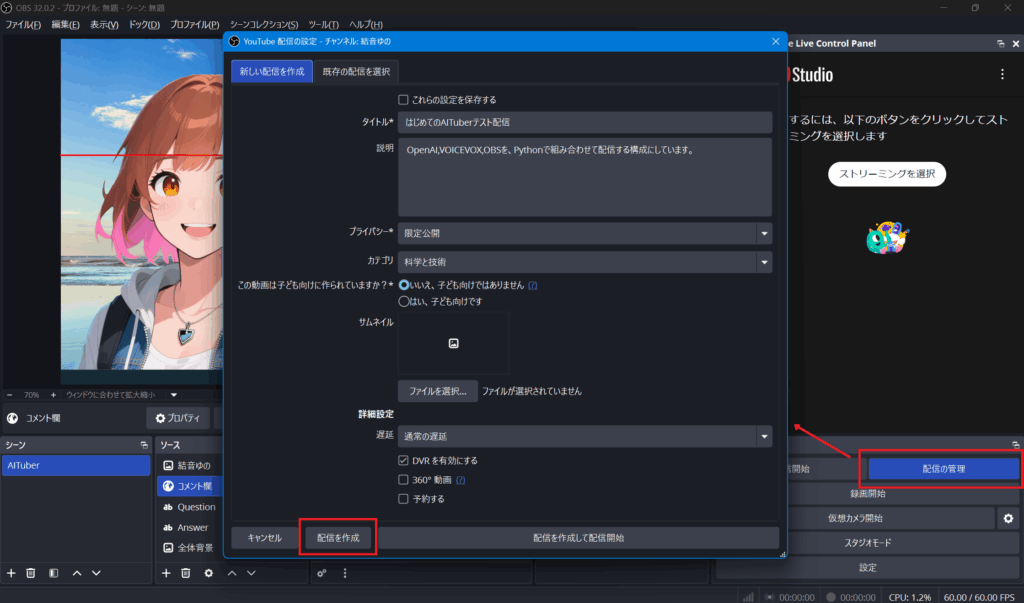
1. OBSにて、コントロールの`配信の管理`を押下
配信の設定をして、`配信の作成`を押下
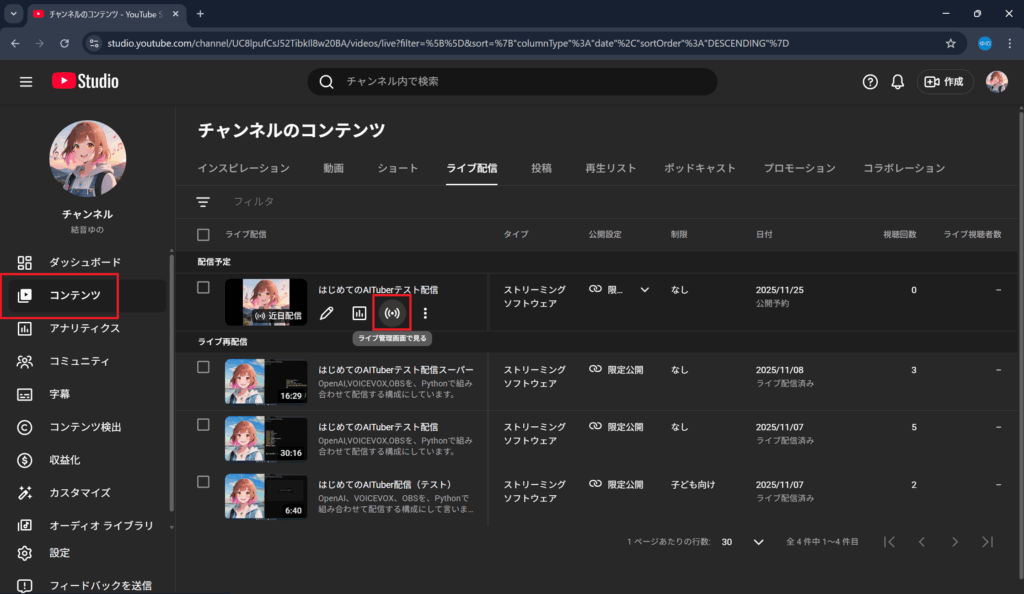
2. YouTube Studioにて、`コンテンツ` > `ライブ配信` を選択し、配信予定で表示されているサムネイルの横にある`ライブ管理画面で見る`をクリック
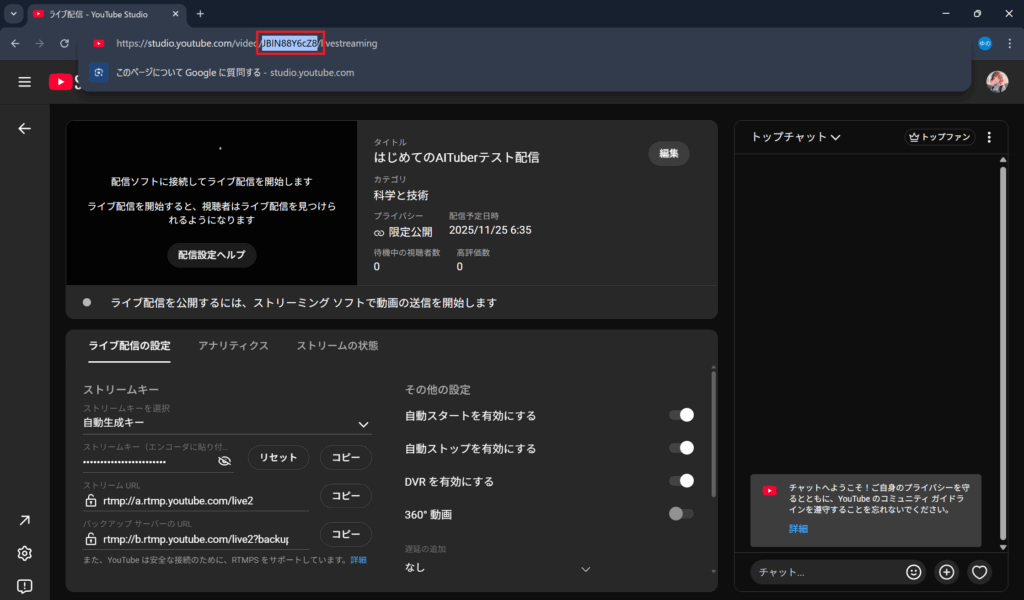
3. VIDEO_IDをURLからコピー。下記の`@@@@@`部分
`studio.youtube.com/video/@@@@@/livestreaming`
4. OBSのコメント欄のプロパティにて、VIDEO_IDを更新。
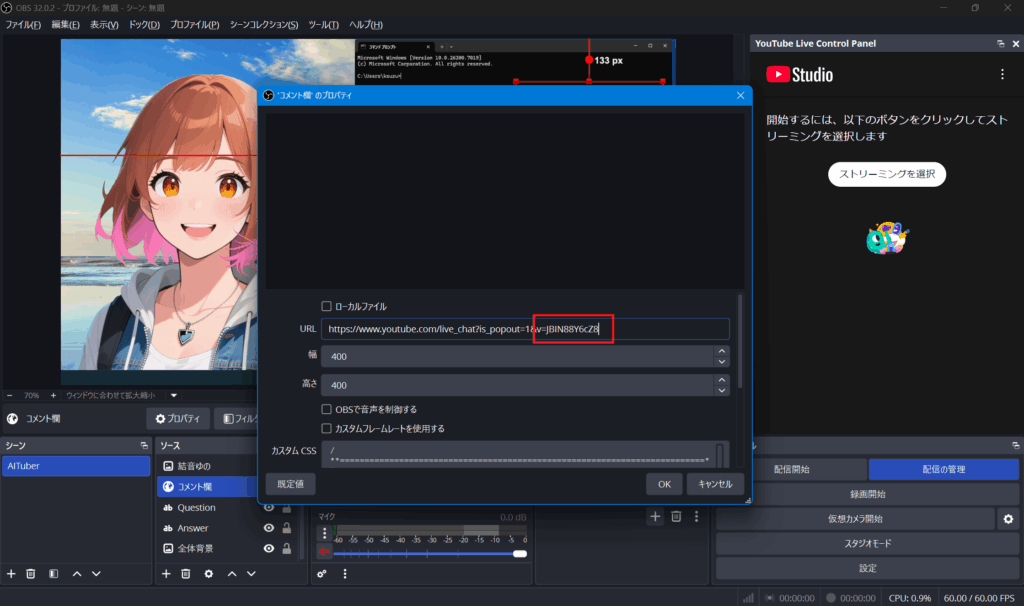
5. .envの環境変数`YOUTUBE_VIDEO_ID`を更新。
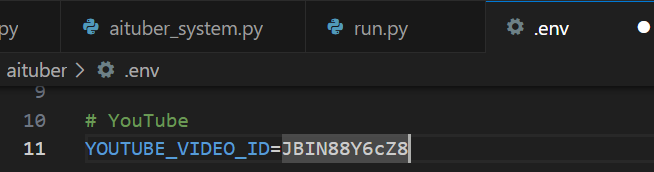
6. 仮想環境を稼働
> cd ※.venvがあるフォルダ※
> .venv\Scripts\activate.bat
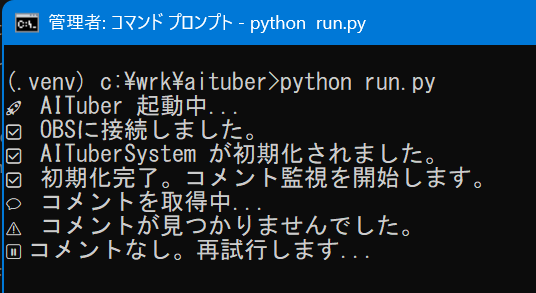
7. 連携したシステムを稼働
> python run.py
8. OBSにて、`配信開始`を押下
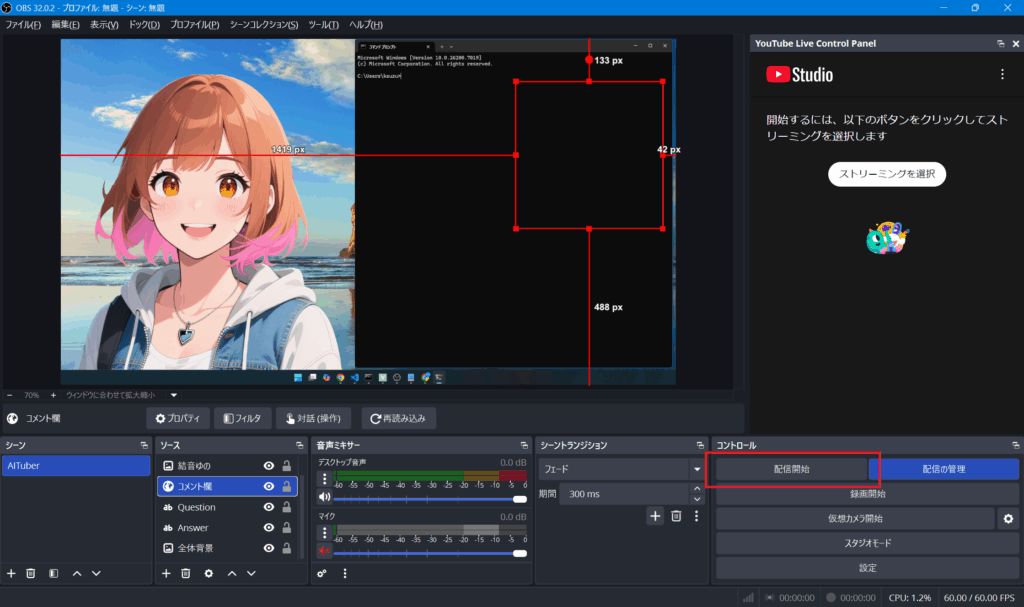
管理画面にて、下記状態となったら問題なくストリーミングができている。出来ていない場合は手順を再確認。
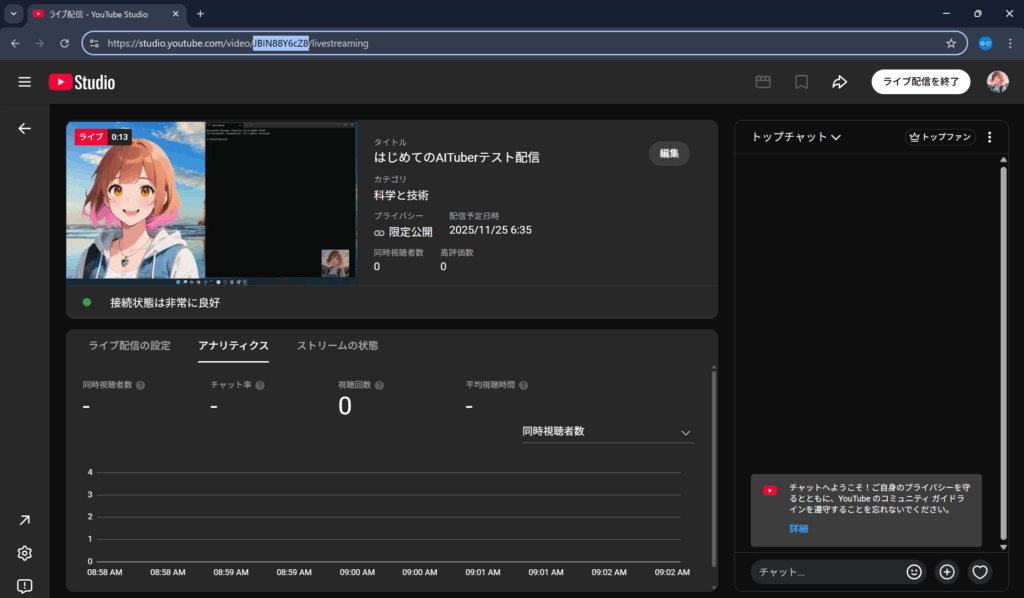
9. 管理画面の右下にチャット欄があるため、そちらに何かチャットを入力
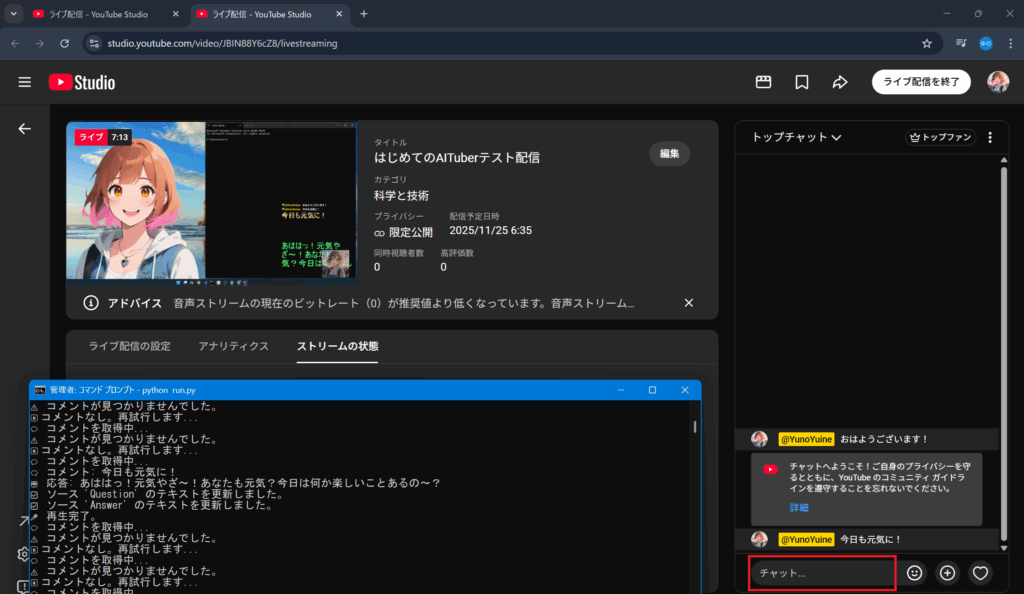
10. これで各機能が確認できたはず!
- OBSへのコメント欄の反映
- コメント欄からQuestionの取得
- OpenAIによるAnswer文言の生成
- OBSへのQuestionとAnswerの反映
- YouTubeのライブ配信からVOICEVOXで音声の出力
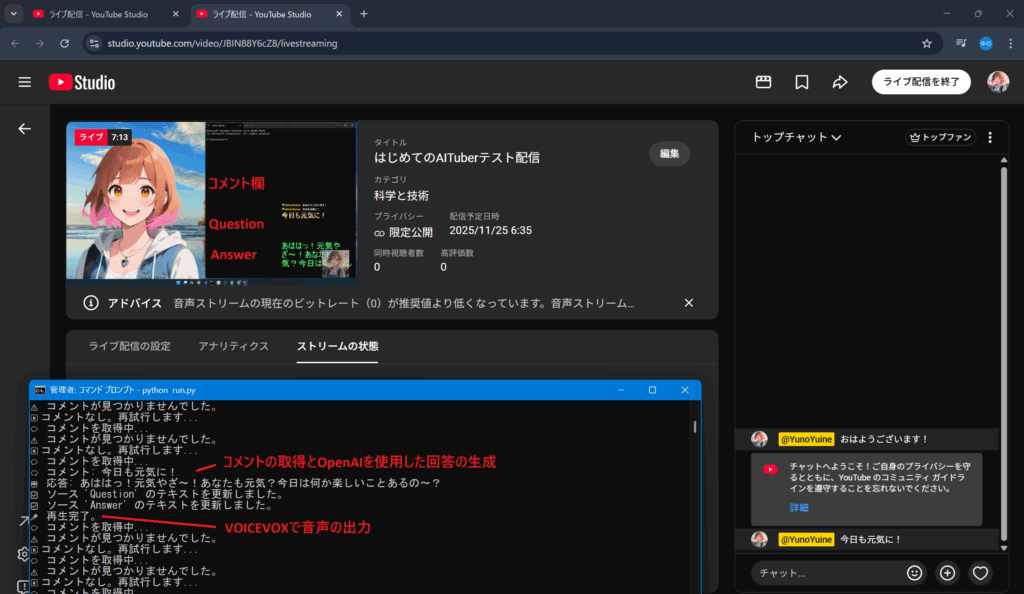
11. 確認ができればこれで完了。
以下で配信とシステムを止めます。
- YouTube Studioにて、`ライブ配信を終了`を押下
- OBSにて、`配信終了`を押下
- 稼働しているシステムを`Esc`押下で停止
それぞれの機能が確認できない場合、再度手順を見直してみましょう。
また、もしかしたらプログラムで利用しているライブラリ等の利用の仕方が変わっているかもしれません。
その辺りは各自で確認して修正していっていただければと思います。
まとめ
色々なAPIやライブラリ等を連携したシステムの実装ができるハンズオンだった。
- Pythonの仮想環境を使用したシステムの構築
- OpenAIのAPI利用
- VOICEVOXのAPI利用
- OBSのWebソケットを利用、ストリーミング機能の利用
- YouTubeのコメント取得
OpenAIのAPIについて、利用方法や価格等について実体験として知ることが出来たのは良かった。(これぐらいでは意外とトークンの消費は少ない)
また、自分が作ったキャラクターが自動で回答してくれるというのはやはり嬉しいもの。
赤松健先生の`A・Iが止まらない`が好きだった過去も思い出し、思いがけず充実したハンズオンだった。
しかし、正直なところ、実際にこの形でAITuberを運用するというのは現実的ではない。
現状では、OpenAIで質問に対して回答を生成し、そのテキストを色々なものをくっつけて豪勢に出力をした、という程度。
自身のペルソナを保持したり、DBに接続することで配信に来てくれた人との交流を長期記憶させたり、感情を持ち、表情や動きを変えたりと、色々したくなった。
- 人間味があるというレベルではなく、一人の人間のように魂を持っているようにふるまってもらいたい
- VOICEVOXの声を好みのオリジナルにしたいし、抑揚とかもこだわりたい
- 2D・3Dにしたいし、魅力あるキャラにしたい
- 自分で作曲をして、歌詞も自分であてて、自作の歌を歌ってもらいたい
- 自分の好きなものをどんどんPRしたい
- 企業が求めるレベルでチューニングしていきたい
今回作成した`結音ゆの`ちゃん、育てていけたらと思う。
